บทนำ
จากตอนที่ 2 และ 3 ผู้อ่านได้เห็นแล้วว่าระบบ Edge AI มีข้อจำกัดด้านทรัพยากรอย่างชัดเจน ไม่ว่าจะเป็นพลังประมวลผล หน่วยความจำ พลังงาน หรือความร้อน แม้ฮาร์ดแวร์บน Edge จะพัฒนาอย่างรวดเร็ว แต่ โมเดล AI ที่ถูกออกแบบมาสำหรับ Cloud ไม่สามารถนำมารันบน Edge ได้โดยตรงในหลายกรณี
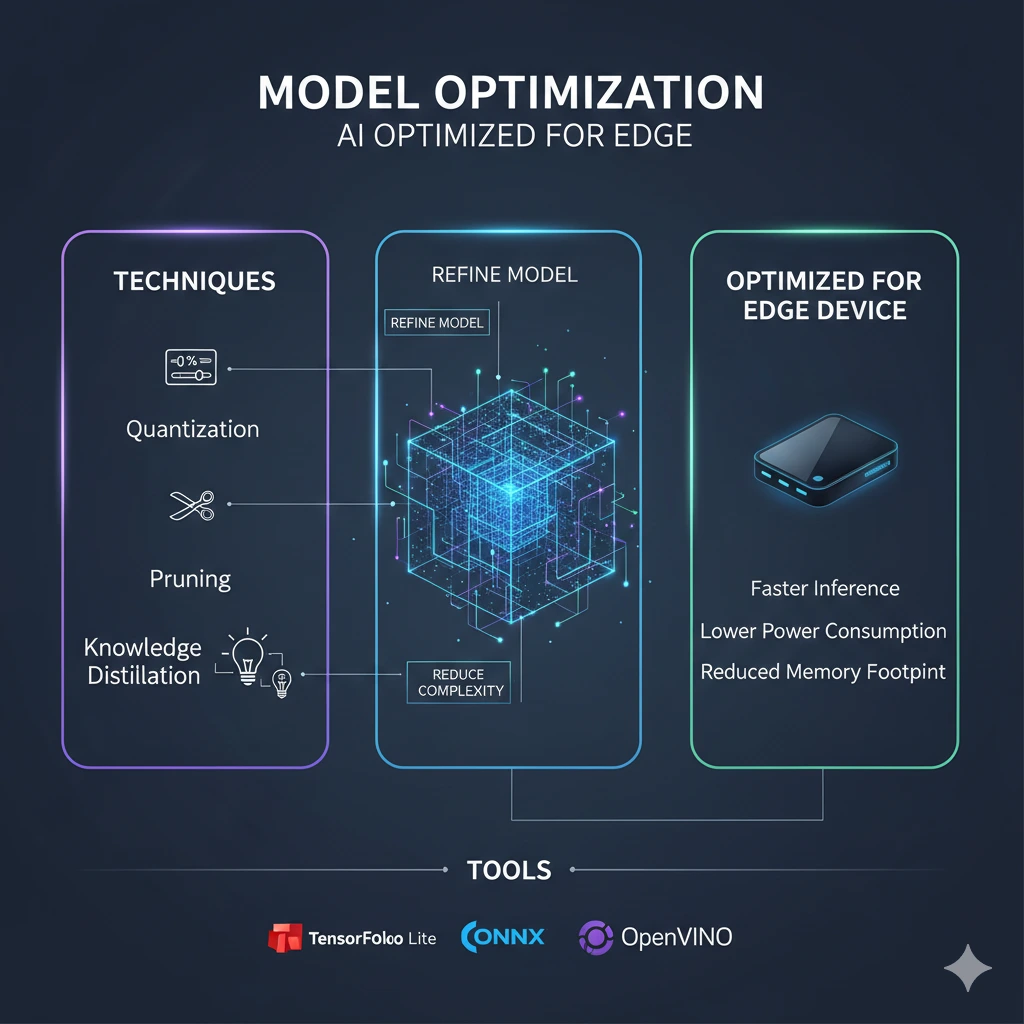
ดังนั้น “Model Optimization” จึงไม่ใช่ขั้นตอนเสริม แต่เป็น หัวใจสำคัญของการนำ AI ไปใช้บน Edge Device บทความนี้มีเป้าหมายเพื่ออธิบายเทคนิคหลักในการปรับแต่งโมเดล ได้แก่ Quantization, Pruning และ Knowledge Distillation รวมถึงเครื่องมือที่นิยมใช้ และตัวอย่างการลดขนาดโมเดลในเชิงปฏิบัติ
1. เหตุใด Model Optimization จึงจำเป็นสำหรับ Edge AI
โมเดล AI สมัยใหม่ โดยเฉพาะ Deep Neural Networks มักถูกพัฒนาในสภาพแวดล้อมที่มีทรัพยากรสูง เช่น GPU หรือ TPU บน Cloud ส่งผลให้โมเดลมีลักษณะดังนี้
ขนาดไฟล์ใหญ่ (หลายสิบถึงหลายร้อย MB)
ใช้หน่วยความจำสูง
ต้องการพลังประมวลผลต่อเนื่อง
ไม่เหมาะกับการทำงานแบบ real-time บน Edge
ในบริบทของ Edge AI เป้าหมายของ Model Optimization คือ
ลดขนาดโมเดล (Model Size)
ลดเวลา inference (Latency)
ลดการใช้พลังงาน
รักษาความแม่นยำให้อยู่ในระดับยอมรับได้
2. Quantization: ลดความละเอียดของตัวเลขเพื่อเพิ่มประสิทธิภาพ
2.1 หลักการของ Quantization
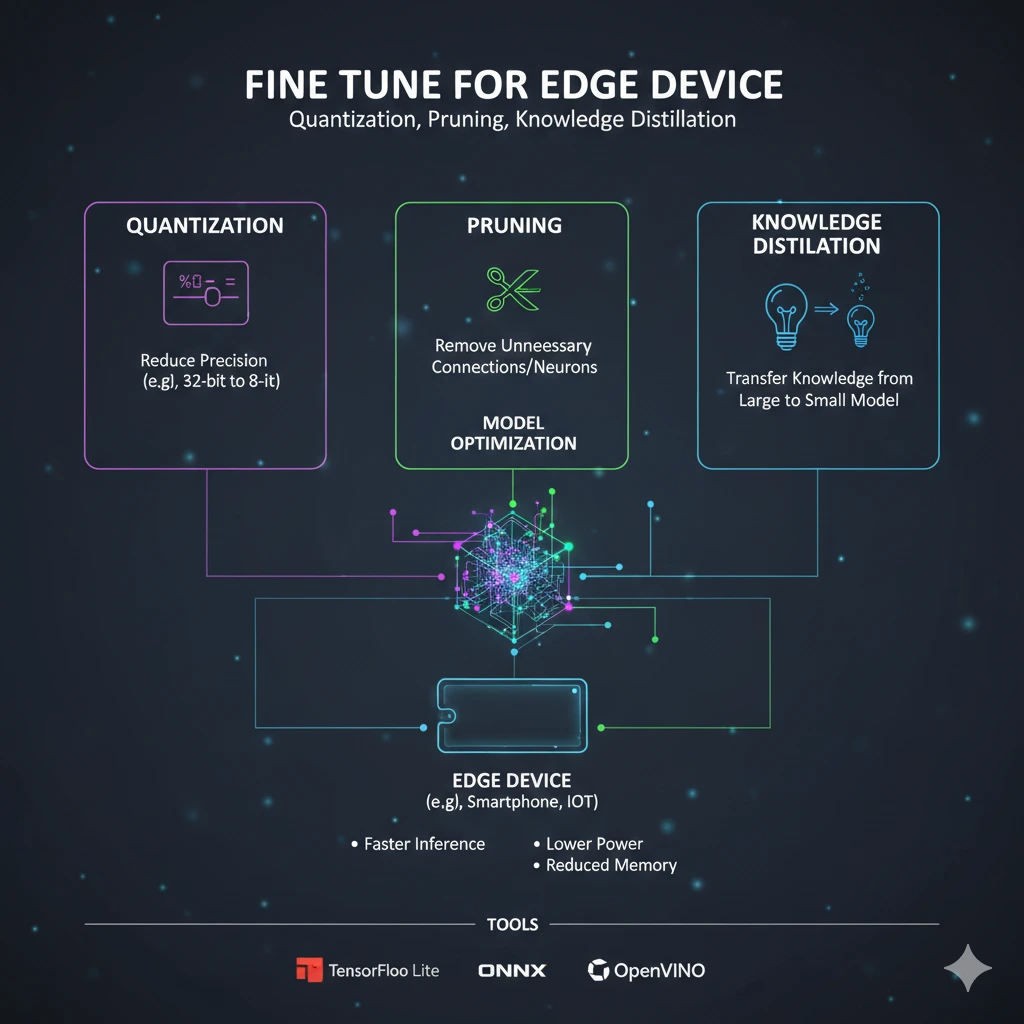
Quantization คือการลดความละเอียดของตัวเลขที่ใช้แทนน้ำหนักและ activation ในโมเดล จากเดิมที่มักใช้เลขทศนิยมแบบ 32-bit floating point (FP32) ให้เหลือ 16-bit (FP16) หรือ 8-bit integer (INT8)
แนวคิดหลักคือ
โมเดล AI ไม่จำเป็นต้องใช้ความละเอียดสูงสุดเสมอไปเพื่อให้ได้ผลลัพธ์ที่ดี
2.2 ประเภทของ Quantization
Post-Training Quantization (PTQ)
ทำหลังจากฝึกโมเดลเสร็จ เหมาะกับการใช้งานจริงและทำได้ง่าย
Quantization-Aware Training (QAT)
จำลองผลของ quantization ระหว่างการฝึก ทำให้ความแม่นยำลดลงน้อยกว่า
2.3 ผลลัพธ์ที่ได้
ขนาดโมเดลลดลง ~4 เท่า (FP32 → INT8)
Latency ลดลงอย่างมีนัยสำคัญ
ใช้พลังงานต่อ inference ต่ำลง
Quantization เป็นเทคนิคพื้นฐานที่แทบทุกโครงการ Edge AI ควรพิจารณาเป็นอันดับแรก
3. Pruning: ตัดส่วนที่ไม่จำเป็นของโมเดล
3.1 แนวคิดของ Pruning
Pruning คือการตัด neuron หรือ weight ที่มีความสำคัญต่ำออกจากโมเดล โดยอาศัยข้อสังเกตว่าโมเดลขนาดใหญ่มักมีความซ้ำซ้อนภายในสูง
กล่าวอีกนัยหนึ่ง โมเดลจำนวนมากมี “พารามิเตอร์ที่แทบไม่มีผลต่อผลลัพธ์สุดท้าย”
3.2 ประเภทของ Pruning
Unstructured Pruning
ตัด weight รายตัว (ได้โมเดลเล็กลง แต่เร่งความเร็วได้ยาก)
Structured Pruning
ตัดเป็นกลุ่ม เช่น channel หรือ layer (เหมาะกับ Edge Hardware มากกว่า)
3.3 ข้อจำกัดของ Pruning
ต้อง fine-tune โมเดลหลัง pruning
หากตัดมากเกินไป ความแม่นยำจะลดลงอย่างชัดเจน
ต้องพิจารณาความสามารถของ hardware ร่วมด้วย
4. Knowledge Distillation: สอนโมเดลเล็กให้เก่งเหมือนโมเดลใหญ่
4.1 แนวคิด Teacher–Student
Knowledge Distillation เป็นเทคนิคที่ใช้โมเดลขนาดใหญ่ (Teacher) ถ่ายทอดความรู้ให้โมเดลขนาดเล็ก (Student)
แทนที่ Student จะเรียนรู้จาก label จริงเพียงอย่างเดียว จะเรียนรู้จาก “พฤติกรรมการทำนาย” ของ Teacher ด้วย
4.2 ข้อดีสำหรับ Edge AI
ได้โมเดลขนาดเล็กตั้งแต่ต้น
ความแม่นยำดีกว่าการฝึกโมเดลเล็กโดยตรง
เหมาะกับ use case ที่ต้อง deploy จำนวนมาก
Knowledge Distillation มักใช้ร่วมกับ Quantization และ Pruning เพื่อให้ได้ผลลัพธ์ที่ดีที่สุด
5. เครื่องมือสำหรับ Model Optimization บน Edge
5.1 TensorFlow Lite (TFLite)
รองรับ Quantization (FP16, INT8)
เหมาะกับอุปกรณ์ ARM เช่น Raspberry Pi, Mobile
Ecosystem ใหญ่และเริ่มต้นง่าย
อ้างอิง:
TensorFlow Lite Documentation, Google
5.2 ONNX และ ONNX Runtime
มาตรฐานกลางสำหรับแลกเปลี่ยนโมเดล
รองรับ optimization และ hardware acceleration
ใช้ได้กับหลายแพลตฟอร์ม
อ้างอิง:
ONNX: Open Neural Network Exchange, Linux Foundation
5.3 Intel OpenVINO
ออกแบบมาสำหรับ inference efficiency
รองรับ CPU, GPU, VPU ของ Intel
เด่นด้าน optimization สำหรับ Computer Vision
อ้างอิง:
Intel OpenVINO Toolkit Documentation
6. ตัวอย่างการลดขนาดโมเดลจริง (เชิงแนวคิด)
ตัวอย่าง: โมเดล CNN สำหรับ Image Classification
| ขั้นตอน | ขนาดโมเดล | ความแม่นยำ |
|---|---|---|
| โมเดลต้นฉบับ (FP32) | 100 MB | 92% |
| Quantization (INT8) | 25 MB | 90–91% |
| + Pruning | 15 MB | 89–90% |
| + Distillation | 12 MB | ~90% |
จากตัวอย่างจะเห็นว่า การยอมลดความแม่นยำเพียงเล็กน้อย สามารถแลกกับประสิทธิภาพที่เพิ่มขึ้นอย่างมาก ซึ่งเป็น trade-off ที่เหมาะสมสำหรับ Edge AI
7. มุมมองเชิงระบบ: Optimization ไม่ใช่แค่เรื่องโมเดล
สิ่งที่มักถูกเข้าใจผิดคือ Model Optimization เป็นเรื่องของ Data Scientist เท่านั้น ในความเป็นจริง การทำ Edge AI ให้สำเร็จต้องพิจารณาร่วมกันระหว่าง
โมเดล
ฮาร์ดแวร์
Framework และ Runtime
ลักษณะงานจริง (Latency, Throughput, Power)
ดังนั้น Model Optimization ควรถูกมองเป็นส่วนหนึ่งของ System Design ไม่ใช่เพียงขั้นตอนก่อน deploy
บทสรุป
Model Optimization เป็นสะพานเชื่อมระหว่าง “AI ในห้องทดลอง” และ “AI ในโลกจริง” สำหรับ Edge Device เทคนิคอย่าง Quantization, Pruning และ Knowledge Distillation ช่วยให้โมเดลมีขนาดเล็กลง เร็วขึ้น และใช้ทรัพยากรอย่างมีประสิทธิภาพ โดยยังคงคุณค่าทางธุรกิจไว้ได้
เมื่อผู้อ่านเข้าใจแนวคิดเหล่านี้ จะสามารถเลือกวิธีปรับแต่งโมเดลได้อย่างเหมาะสม ก่อนนำไปใช้งานบน Edge
เกริ่นสู่ตอนที่ 5
เมื่อโมเดลพร้อมแล้ว คำถามถัดไปคือ
เราควรเลือกฮาร์ดแวร์แบบใดสำหรับ Edge AI?
ในตอนที่ 5 เราจะพาไปสำรวจฮาร์ดแวร์ตั้งแต่ Raspberry Pi ไปจนถึง Specialized Chips และเกณฑ์การเลือกที่เหมาะกับงบประมาณและ use case จริง
แหล่งอ้างอิง (References)
Han et al., Deep Compression, ICLR
Hinton et al., Distilling the Knowledge in a Neural Network, NIPS Workshop
Google, TensorFlow Lite Guide
Intel, OpenVINO Toolkit Documentation
ONNX, Open Neural Network Exchange